references:
Understanding Diffusion Models: A Unified Perspective https://arxiv.org/abs/2208.11970
Denoising Diffusion Probabilistic Models https://arxiv.org/abs/2006.11239
近年来,Diffusion Model在图像/视频生成领域以及VLA模型都表现出优异性能,本文参考上述文献,试图以简单扼要的篇幅解释清楚Diffusion Model的数学原理,适合有CS和Machine Learning背景的读者快速入门。
Introduction
生成模型领域有几个well-known的方向,包括 Generative Adversarial Networks (GANs),likelihood-based,energy-based以及score-based,Variational Diffusion Models (VDM) 的数学原理可以从多个方向进行解释,本文选择likelihood-based,个人认为比较好理解。
likelihood-based的方法的核心思想是:给定一个数据集,训练模型来最大化数据集中样本(evidence)的出现概率(likelihood),进而拟合到,即数据的真实分布。这类方法中最具代表性的就是Variational Autoencoders (VAEs),而VDM可以认为VAE的一个变体,因此本文从VAE讲起,逐步递进至VDM。
VAE
likelihood-based生成模型的核心目标是拟合出数据的真实分布($P_{\phi}(x) \rightarrow P(x)$),但只有数据分布还不够,因为数据生成过程本质是在真实的数据分布中采样,对于一个完全未知的复杂分布是很难采样的,因此,VAE借助一个随机变量和自定义分布$P(z)$(一般选择多维的标准高斯分布$N~(z; 0,I)$ ),并通过$q(z|x)$(Encoder)和$p(x|z)$(Decoder)将$z$和$x$建立起联系。这样,对符合高斯分布的$z$采样,就能通过Decoder得到一个新的生成数据$x’$,$z$被叫做隐变量(latent variable)。
所谓Variational Autoencoders,Autoencoder是指通过编解码的过程,将数据压缩至低维空间;Variational是指对隐空间(latent space)施加约束,迫使它成为正态分布,进而为整个数据空间提供了生成能力。
然而直接最大化likelihood是困难的,最大化某个复杂变量常用的方法是最大化它的某个下界。由引理1可以把likelihood 拆成两项,即和,KL散度的定义决定了它是大于等于0的,所以第一项就是likelihood的一个下界,称做Evidence Lower Bound (ELBO)。
进一步分析最大化ELBO是在做什么,由lemma 1得 ,等号左边和参数$\Phi$没关系(可以视作关于$\Phi$ 定值),因此通过调整参数$\Phi$来最大化ELBO,实际上就是在最小化$q_{\phi}(z|x)$Encoder和真实的后验概率$p(z|x)$之间的KL散度,这正是我们想要的。完美!
这里你可能想问,最大化ELBO就是在优化encoder了,那decoder在哪里优化呢?答案就是在ELBO里面了,接下来继续分析ELBO。
由lemma 2可知,,最大化ELBO就是要最大化第一项并最小化第二项。拆开来看,第一项是在Decoder从隐变量z生成原始数据x的概率,被称为reconstruction term,用于优化Decoder;第二项是由Encoder映射到的隐变量z分布和指定的分布$p(z)$之间的KL散度,被称作prior matching term,用于优化Encoder。
这里结合一下VAE模型的实际实现,进一步理解上述的两个优化项在工程中是如何实现的。在实际的VAE的模型中,Encoder拟合的变分分布通常被假设为一个对角高斯(各维度独立的正态分布),即,而prior分布$p(z)$通常选取标准的多元高斯$N(z; 0, I)$。对于prior matching term,KL散度是可以直接计算的;对于reconstruction term,期望的计算则往往利用蒙特卡洛估计进行近似,即
而直接采样的操作是不可导的,需要用重参数化技巧,非本文重点不多展开。
MHVAE (Markovian Hierarchical Variational Autoencoders)
MHVAE是一种特殊的VAE,它引入了T个隐变量$z_{1:T}$,将编/解码的过程分成T步,也就是所谓的级联Hierarchical。同时,每一步的编/解码只和它的上一步状态有关,和更早的状态无关,即马尔可夫性质Markovian。
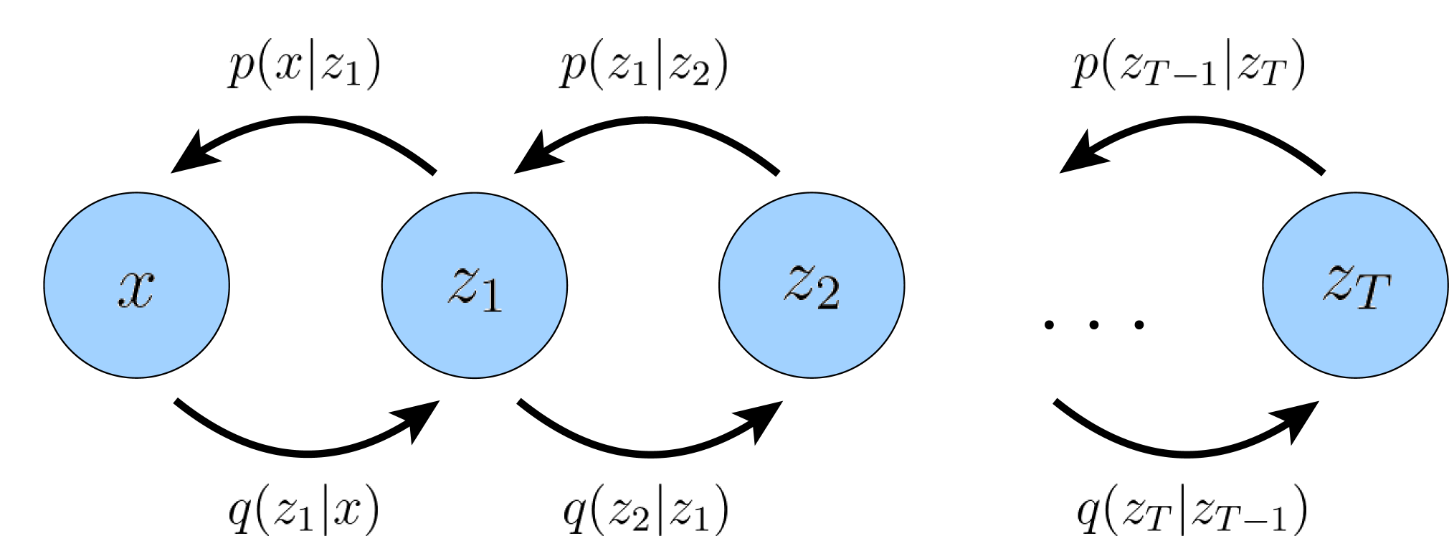
由lemma 1易得,。
VDM (Variational Diffusion Model)
VDM是MHVAE在以下三个限制条件的特例:
- 数据$x$和所有隐变量$z_t$的维度相同;
- 所有的encoder $q(zt|z{t-1})$都是预定义好的高斯分布模型(不需要学习),即$zt$状态为以$z{t-1}$为均值的高斯分布;
- 最终T状态的分布$z_T$为标准高斯分布。
这里做一下符号变换 ,限制1和2指定了, 是VDM中的超参,一般认为指定,有些后续方法也将其设定为可学习。限制3指定。
既然VDM是VAE的变体,那思路不变,最大化Evidence的过程依然是去最大化ELBO,接下来就讲一下如何获得VDM的ELBO。
由lemma 3可得,,接下来看一下这三项的物理含义。
- 第一项被称作reconstruction term,表示的是基于第一步的隐变量原始数据分布的log probability;
- 第二项被称作prior matching term,表示最后一步的encode分布和最终隐变量的分布之间的KL散度,其中没有可优化的参数,由于我们假设在T足够大时$p(x_T)$也是高斯,这一项可以视作0;
- 第三项被称作consistency term,表示对于某个中间隐状态,denoising step from a noisier image should match the corresponding noising step from a cleaner image。
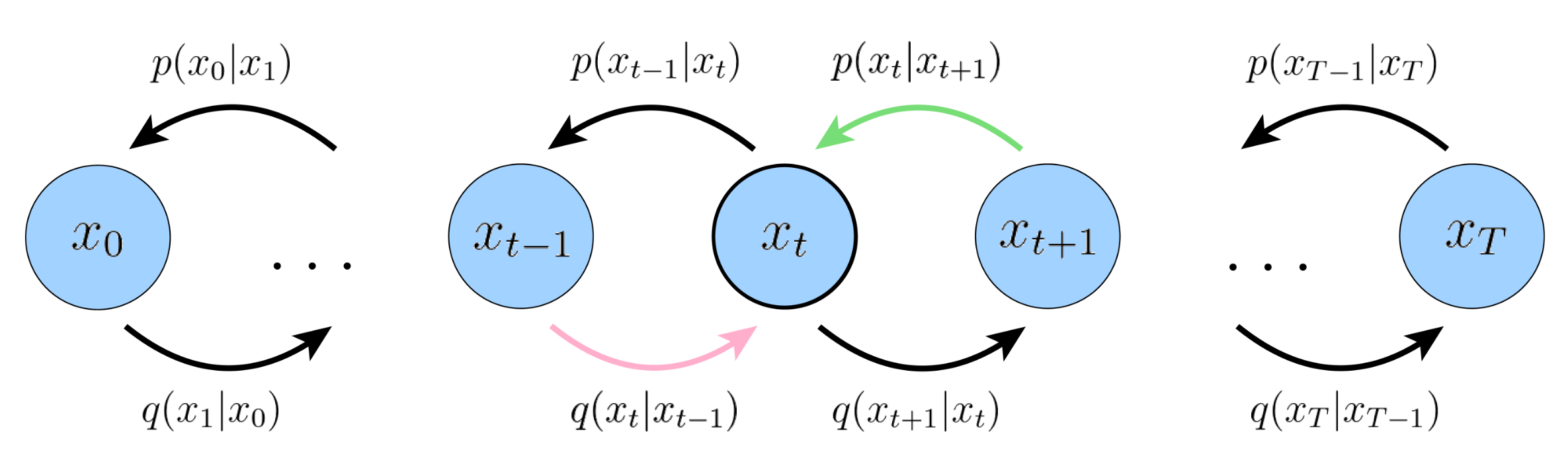
目前ELBO中的三项都是期望,需要通过蒙特卡洛方法进行估计,然而对于consistency term,它依据的两个随机变量(和)的期望,这会使得方差变大,估计值更加不准,因此需要进一步推导。
利用马尔可夫性质和贝叶斯公式,可得,将这个关键步骤带入ELBO得推导过程(具体过程见lemma 4),可得 。第一项和VAE类似不再赘述,第二项没有可优化参数可以忽略,重点关注第三项,$q(x_{t-1}|x_t,x_0)$是未知分布,直接拟合是比较困难的,需要对其进行进一步推导。
由于$q(xt|x{t-1})$是预定义好的高斯分布,容易想到用贝叶斯公式对进项转化,,但其中还带了 和,由lemma 5得,它们也是高斯分布,,其中。带入推导过程,可以得到也是一个高斯分布(具体过程见lemma 6), 。我们假设也是高斯分布,由于以及在这个分布中都是给定的,为了方便对应,可以将的形式设置为,那么两个高斯分布直接之间KL散度就可以转化为和之间的差距了,由lemma 7可得,
到目前为止,优化目标已经被转为训练一个映射$\hat x_\theta$,它基于步数t和第t步得隐变量$x_t$,恢复出$x_0$,这已经是一个可训练的目标了。另外,还可以利用$x_0 = \frac{x_t-\sqrt{1-\overline\alpha_t}\epsilon_0}{\sqrt{\overline\alpha_t}}$,将优化目标转化为预测第t步加在$x_0$上的噪声(具体过程见lemma 8)。实践结论表明,预测噪声效果会更好,DDPM就是使用这种方式。
Lemmas
lemma1: 拆分likelihood获得ELBO
lemma2: ELBO分解
lemma3: VDM ELBO推导1
- VDM ELBO推导2